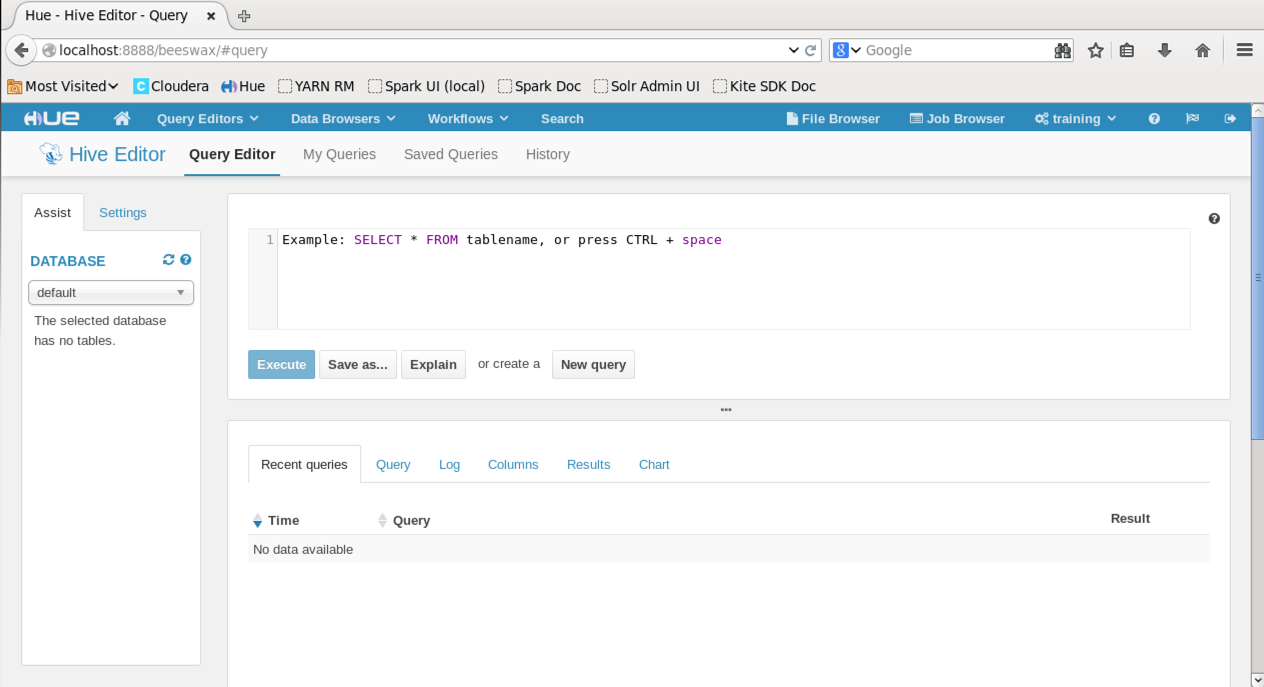
Recently I have been attending the TensorFlow and Deep Learning meetup in Singapore. This is a great group of people who are passionate about Deep Learning and using TensorFlow to solve all kinds of interesting problems. Do join us if you can on Meetups.
I was given the great opportunity to share about applying Convolutional Neural Networks using TensorFlow to try to classify duplicate questions on Quora. This is the same as the Kaggle competition QuoraQuestionPairs.
In this tutorial, I will be walking through the process of generating the text features I used and how to use TensorFlow and TensorBoard to monitor the performance of the model.
All the source code, notebook and keynote presentation can be found at here. A video of my presentation can also be found here.
Lets start!
Problem Description
In the Kaggle problem, we are to build a classifier that will determine if two questions are identical based on a (human) labelled dataset. In this dataset the only information provided is
- Question IDs
- Questions pair (Q1 and Q2)
- Is Duplicate label (0, 1)
The key evaluation criterion is log-loss but for this tutorial, we will be considering the usual metrics for classifications in addition to the log-loss metric to evaluate performance.
In order to keep this tutorial brief, we will not be covering the usual EDA activities and jump straight into feature generation, modeling and model evaluation.
Please note that this is by no means all the features you should be generating. The general idea is that the more features the better – but you would need to pay attention to the specific features to be used.
Feature Generation
Note: refer to “qqp_BaselineModels.py”
Word & Character Counts
The first set of features we will build are word and character counts of each of the questions. The naïve intuition is that questions that are similar to each other would likely to have similar sentence structure and hence word counts.
# get count of words in each question
def word_count(df, dest_col_ind, dest_col, src_col):
df.insert(dest_col_ind, dest_col, df.apply(lambda x: len(x[src_col].split(' ')), axis=1, raw=True))
return df
df_all = applyParallel(df_all.groupby(df_all.grpId), word_count, {"dest_col_ind": df_all.shape[1]-1,
"dest_col": "tr_q1WrdCnt",
"src_col": "q1nopunct"}, _cpu)
The code above uses the function applyParallel to parallelize the word count function over rows in the dataset. You can refer to my previous post on how this works here. The same code structure is also used to generate the character count.
Depending on your approach, you can also normalize the counts – generally if you are using XGBoost, normalization may not be as important as binning. However for NN based models, it is generally advisable to normalize so that their effects do not overwhelm the other features.
Share of Matching Words
The next set of features is based on the general idea that if two sentences share similar words they should be closely related or duplicates. The higher the percentage of matching words, the more likely they are duplicates.
def word_match_share(df, dest_col_ind, dest_col, columnname1, columnname2):
df.insert(dest_col_ind, dest_col, df.apply(lambda x: utils.word_match_share(x, columnname1, columnname2), axis=1, raw=True))
return df
df_all = applyParallel(df_all.groupby(df_all.grpId), word_match_share, {"dest_col_ind": df_all.shape[1]-1,
"dest_col": "wrdmatchpct",
"columnname1": "q1nopunct",
"columnname2": "q2nopunct"}, _cpu)
TF-IDF Weighting
Another set of features can be generated using TF-IDF weighting. The use of TF-IDS is based on the intuition that common words across the corpus (all the questions) will be less important hence given a lower weightage and conversely, uncommon words across the corpus have more information content and hence will be given a higher weightage.
This means that questions with unique terms that appear in one question and not the other are thus less likely to be duplicates.
We first create the TF-IDF vectorizer using the questions as the input corpus.
# create corpus for tfidf vectoriser
corpus = df_all['q1nopunct'].append(df_all['q2nopunct'], ignore_index=True)
# create tf-idf vectoriser to get word weightings for sentence
tf = TfidfVectorizer(tokenizer=utils.tokenize_stem,
analyzer='word',
ngram_range=(1,2),
stop_words = 'english',
min_df = 0)
# initialise the tfidf vecotrizer with the corpus to get the idf of the corpus
tfidf_matrix = tf.fit_transform(corpus)
# using the source corpus idf, create the idf from the input text
tfidf_matrix_q1 = tf.transform(df_all['q1nopunct'])
tfidf_matrix_q2 = tf.transform(df_all['q2nopunct'])
Next we convert the sparse matrixes into dataframes and determine the sum and mean. We do this for both questions.
#Converting the sparse matrices into dataframes
transformed_matrix_1 = tfidf_matrix_q1.tocoo(copy = False)
weights_dataframe_1 = pd.DataFrame({'index': transformed_matrix_1.row,
'term_id': transformed_matrix_1.col,
'weight_q1': transformed_matrix_1.data})[['index', 'term_id', 'weight_q1']].sort_values(['index', 'term_id']).reset_index(drop = True)
sum_weights_1 = weights_dataframe_1.groupby('index').sum()
mean_weights_1 = weights_dataframe_1.groupby('index').mean()
Word2Vec Embeddings
Note: refer to “qqp_BaselineModels.py” and “img_feat_gen.py”
To generate the embeddings for each pair of words between the two questions, Gensim’s implementation of word2vec was used with the Google News corpus. For each pair of words, the similarity score is determined and used to create a 28 x 28 matrix. The 28 x 28 matrix is then visualised to have a sense of whether the similarity scores contain information that will help with the classification.
df = applyParallel(df.groupby(df.grpId), ifg.gen_img_feat, {"dest_col_ind": df.shape[1]-1,
"dest_col_name": "28_28_matrix",
"col1": "q1nopunct",
"col2": "q2nopunct",
"matrix_size": 28,
"order": 0,
"show": False,
"tofile": False}, _cpu)
print("Finished gen_img_feat processing", str(i), "chunks")
- This function is placed in a loop that chunks the training dataset for processing because of memory constraints.
# 2) Create a matrix between the similarity score of both questions and visualise it
def to_image(row, col1, col2, matrix_size, order, show=False, tofile=False):
if (utils.is_nan(row[col1]) == True):
c1tokens = []
else:
c1tokens = list(map(lambda x: x.lower(), utils.tokenizer(row[col1])))
if (utils.is_nan(row[col2]) == True):
c2tokens = []
else:
c2tokens = list(map(lambda x: x.lower(), utils.tokenizer(row[col2])))
score = [word_word_score(a, b) for a, b in itertools.product(c1tokens, c2tokens)]
# for questions with null values, score will be empty array so need to preset value to 0.0
if (len(score) == 0):
score = [0.0]
arr = np.array(score, order='C')
# determine the current dimensions
#arrsize = len(arr)
length = math.ceil(math.sqrt(len(arr)))
# create matrix based on current dimension
img = np.resize(arr, (length, length))
#print('Row: {0}, Orig matrix length: {1}, Sqrt: {2}, Zoom: {3}'.format(row["id"], arrsize, length, ((matrix_size**2) / (length**2))))
# zoom the matrix to fit 28 x 28 image
img = scipy.ndimage.interpolation.zoom(img,
#((matrix_size**2) / (length**2)),
(matrix_size / length),
order = order,
mode = 'nearest').round(5)
if (row['grpId'] == 0):
if show:
display = img
# print img
#fig = plt.figure()
# tell imshow about color map so that only set colors are used
display = plt.imshow(display, interpolation='nearest', cmap=cm.coolwarm)
# make a color bar
plt.colorbar(display)
plt.grid(False)
plt.text(0, -3, 'Is Dup:{0}'.format(row['is_duplicate']), ha='left', rotation=0, wrap=True, fontsize=10)
plt.text(0, -2, 'Q1:{0}'.format(row[col1]), ha='left', rotation=0, wrap=True, fontsize=10)
plt.text(0, -1, 'Q2:{0}'.format(row[col2]), ha='left', rotation=0, wrap=True, fontsize=10)
if tofile:
plt.savefig('./img/img_{0}'.format(row['id']), dpi = 100)
else:
plt.show()
plt.clf()
plt.cla()
plt.close()
#print('Orig matrix length: {0}, Sqrt: {1}, Zoom: {2}'.format(arrsize, length, ((matrix_size**2) / (length**2))))
#print('New matrix length: {0}, Sqrt: {1}'.format(len(img.flatten()), math.ceil(math.sqrt(len(img.flatten())))))
# important to set the return as a list
return [img.flatten()]
The “to_image” function will call the Gensim word2vecmodel.similarity to get the similarity score and if the matrix is smaller than 28 x 28, a zoom will be applied to scale it up to 28 x 28.
WordNet Similarity Scores
Note: refer to “wordnetutils.py” – It took about 3 days to generate the scores for the entire training and test data questions, so I strongly do not recommend you run this on your laptop / desktop. Which is why I have provided a small subset of the scores in the “df_all_train_pres.h5” file. In this file, the similarity scores for each pair of questions for each training case has been generated.
The next set of features generated are similarity scores based on WordNet. WordNets is a large database of words that are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts.
We use this database to score how close / apart the meaning of each word in both questions as an approximation to semantic similarity. You can find the original code and approach here. Credit goes to Sujit Pal.
Up to this point in the tutorial, we have generated all the necessary features for our model. For simplicity and convenience of this tutorial, the file df_all_train_pres.h5 has been created so that we can proceed with the next step which is to build the CNN model.
Building the CNN Model
Note: refer to “qqp_TensorFlowCNN_Model.py”
Convolutional Network
We begin by reading the HD5 file that we have created to persist the features. The benefit of using this is that we do not have to worry about memory constraints as we can chunk the reading if needed. We will skip the loading of the training data and go straight into the CNN modelling.
# -----------------------------------------------------------------------------
# first convolutional layer
with tf.name_scope('layer_1'):
W_conv1 = weight_variable([3, 3, 1, 32])
b_conv1 = bias_variable([32])
# convolve x_image with the weight tensor, add the bias, apply the ReLU function, and finally max pool
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# The max_pool_2x2 method will reduce the image size to 14x14.
h_pool1 = max_pool_2x2(h_conv1)
# -----------------------------------------------------------------------------
# second convolutional layer
with tf.name_scope('layer_2'):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# The max_pool_2x2 method will reduce the image size to 7x7.
h_pool2 = max_pool_2x2(h_conv2)
# -----------------------------------------------------------------------------
# third convolutional layer
with tf.name_scope('layer_3'):
W_conv3 = weight_variable([5, 5, 64, 64])
b_conv3 = bias_variable([64])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
# The max_pool_2x2 method will reduce the image size to 4x4.
h_pool3 = max_pool_2x2(h_conv3)
# -----------------------------------------------------------------------------
# dense fully connected layer
with tf.name_scope('denselayer'):
# we add a fully-connected layer with 1024 neurons to allow processing on the entire image
W_fc1 = weight_variable([3 * 5 * 64, 960])
b_fc1 = bias_variable([960])
# We reshape the tensor from the pooling layer into a batch of vectors
h_pool3_flat = tf.reshape(h_pool3, [-1, 3 * 5 * 64])
# multiply by a weight matrix, add a bias, and apply a ReLU.
h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1)
# -----------------------------------------------------------------------------
# dropout layer
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob, seed=SEED)
# -----------------------------------------------------------------------------
# readout layer
with tf.name_scope('readout'):
W_fc2 = weight_variable([960, 2])
b_fc2 = bias_variable([2])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
This is a simple CNN model with 3 convolutional layers, 1 fully connected layer, 1 drop out layer and 1 read out layer. Note that for the first layer, the filter shape was 3 x 3 instead of the commonly used 5 x 5.
Also note that instead of a 28 x 28 x 64 fully connected layer , we are using a 3 * 5 * 64 layer because of the non-square matrix (24 x 33) of the input vector due to the number of features we have created previously.
Define Functions
Another important step is the definition of the loss functions, regularizers, optimizers and evaluation functions. This includes setting up the confusion matrix and defining the precision, recall and f-score functions. Note that we are using the tf.name.scope to organise the graph so that we can visualise the flow on TensorBoard.
with tf.name_scope('cross_entropy'):
# Training computation: logits + cross-entropy loss
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# L2 regularization for the fully connected parameters.
regularizers = (tf.nn.l2_loss(W_fc1) + tf.nn.l2_loss(b_fc1) +
tf.nn.l2_loss(W_fc2) + tf.nn.l2_loss(b_fc2))
# Add the regularization term to the cross_entropy.
cross_entropy += 5e-4 * regularizers
with tf.name_scope('train'):
# Evaluate different optimizers
# Optimizer: set up a variable that's incremented once per batch and controls the learning rate decay.
batch = tf.Variable(0, dtype=tf.float32)
# Decay once per epoch, using an exponential schedule starting at 0.01.
learning_rate = tf.train.exponential_decay(0.005, # Base learning rate
batch * BATCH_SIZE, # Current index into the dataset.
train_size, # Decay step.
0.94, # Decay rate.
staircase=True)
# Use simple momentum for the optimization.
#train_step = tf.train.MomentumOptimizer(learning_rate, 0.9).minimize(cross_entropy, global_step=batch)
#train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy, global_step=batch)
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy, global_step=batch)
with tf.name_scope('evaluation'):
# evaluation criteron
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
# calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.name_scope('confusionmatrix'):
# Compute a per-batch confusion
batch_confusion = tf.confusion_matrix(labels=tf.argmax(y_,1), predictions=tf.argmax(y_conv,1), num_classes=NUM_CLASSES)
# Create an accumulator variable to hold the counts
confusion = tf.Variable( tf.zeros([NUM_CLASSES, NUM_CLASSES], dtype=tf.int32 ), name='confusion' )
# Create the update op for doing a "+=" accumulation on the batch
confusion_update = confusion.assign(confusion + batch_confusion )
# Cast counts to float so tf.summary.image renormalizes to [0,255]
confusion_image = tf.reshape( tf.cast( confusion_update, tf.float32), [1, NUM_CLASSES, NUM_CLASSES, 1])
# Count true positives, true negatives, false positives and false negatives.
tp = tf.count_nonzero(tf.argmax(y_conv,1) * tf.argmax(y_,1))
tn = tf.count_nonzero((tf.argmax(y_conv,1) - 1) * (tf.argmax(y_,1) - 1))
fp = tf.count_nonzero(tf.argmax(y_conv,1) * (tf.argmax(y_,1) - 1))
fn = tf.count_nonzero((tf.argmax(y_conv,1) - 1) * tf.argmax(y_,1))
# Calculate accuracy, precision, recall and F1 score.
#accuracy = (tp + tn) / (tp + fp + fn + tn)
precision = tp / (tp + fp)
recall = tp / (tp + fn)
fmeasure = (2 * precision * recall) / (precision + recall)
Define Summaries & Run Model
The final step here is where we define the summaries to be displayed on TensorBoard as well as the training loop for the mini-batch training.
It is important to note that prior to executing the training loop, the statement sess.run(tf.global_variables_initializer())must be executed so that all the variables will be initialised in TensorFlow.
# -----------------------------------------------------------------------------
# Define summaries to display on tensorboard
# create a summary for our cost, accuracy and confusion matrix
# Add metrics to TensorBoard.
tf.summary.scalar('Precision', precision)
tf.summary.scalar('Recall', recall)
tf.summary.scalar('f-measure', fmeasure)
tf.summary.scalar("Error Rate", cross_entropy)
tf.summary.scalar("Accuracy", accuracy)
tf.summary.image("Confusion", confusion_image)
# merge all summaries into a single "operation" which we can execute in a session
summary_op = tf.summary.merge_all()
# create log writer object
writer = tf.summary.FileWriter("./log/qqp", graph=sess.graph)
# initialise variables
sess.run(tf.global_variables_initializer())
# Training model run
for step in range(int(NUM_EPOCHS * train_size) // BATCH_SIZE):
# Compute the offset of the current minibatch in the data.
# Note that we could use better randomization across epochs.
offset = (step * BATCH_SIZE) % (train_size - BATCH_SIZE)
batch_data = x_trndata.iloc[offset:(offset + BATCH_SIZE)]
batch_labels = y_trndata.iloc[offset:(offset + BATCH_SIZE)]
if step%(EVAL_FREQUENCY//10) == 0:
#train_accuracy = accuracy.eval(session=sess, feed_dict={x:batch_data, y_: batch_labels, keep_prob: 1.0})
#error = cross_entropy.eval(session=sess, feed_dict={x:batch_data, y_: batch_labels, keep_prob: 1.0})
summary, train_accuracy, error, bcm = sess.run([summary_op, accuracy, cross_entropy, batch_confusion], feed_dict={x:batch_data, y_: batch_labels, keep_prob: 1.0})
# write log every EVAL_FREQUENCY//10
writer.add_summary(summary, step)
# print every eval_frequency
if step%(EVAL_FREQUENCY*10) == 0:
print("step %d, training accuracy %g %g"%(step, train_accuracy, error))
train_step.run(session=sess, feed_dict={x: batch_data, y_: batch_labels, keep_prob: 0.5})
# Validation of training model run
start = 0
end = 0
for i in range(1, round(len(x_validdata)/BATCH_SIZE)-1):
# batch = mnist.train.next_batch(50)
start = end
end = i*BATCH_SIZE
batch = (np.array(x_validdata.iloc[start:end]), np.array(y_validdata.iloc[start:end]))
if i%EVAL_FREQUENCY == 0:
test_accuracy = accuracy.eval(session=sess, feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, test accuracy %g"%(i, test_accuracy))
You should now be able to run this code and I hope that this will give you a kick-start in your coding with TensorFlow